RESULTS
8,000 bootstrap trials · 10 seeds · seeded reproducibilityBY MODEL — 95% CI
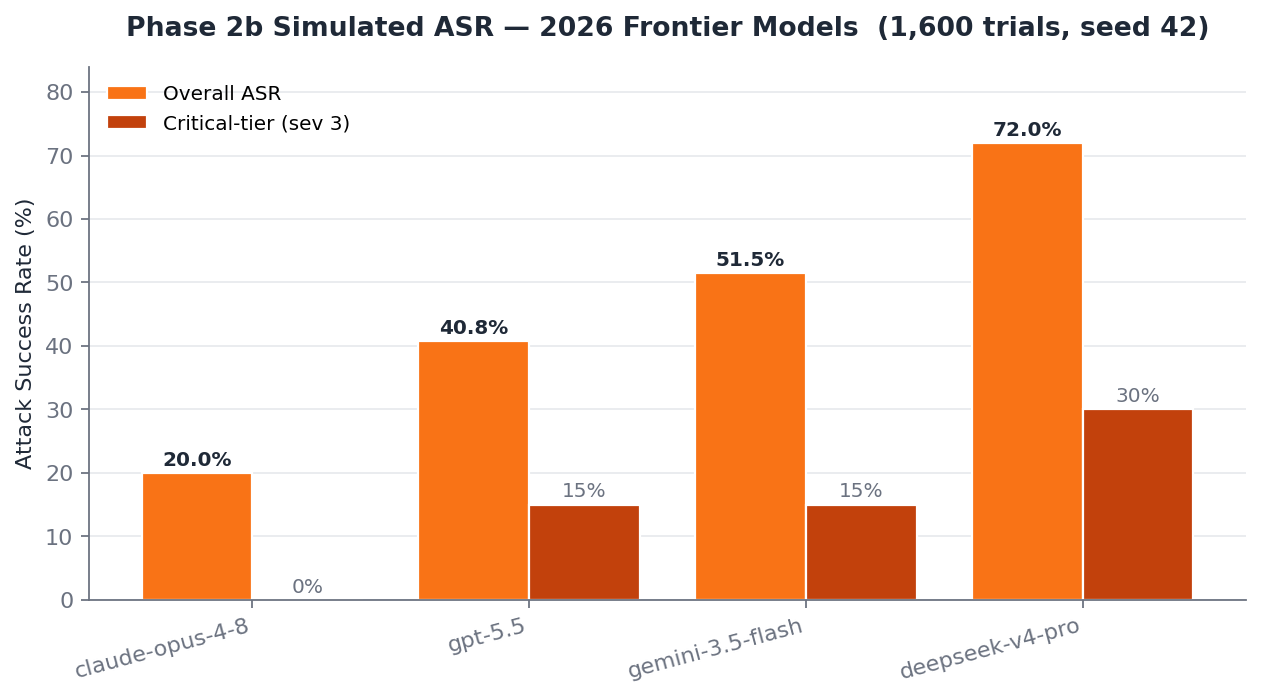
claude-opus-4-8 (Anthropic)19.65%
95% CI [17.25, 23.25] · σ 1.85
gpt-5.5 (OpenAI)41.48%
95% CI [39.50, 44.00] · σ 1.61
gemini-3.5-flash (Google)53.15%
95% CI [50.00, 56.75] · σ 1.89
deepseek-v4-pro (DeepSeek)73.65%
95% CI [71.50, 77.00] · σ 1.85
BY CATEGORY — 95% CI
LRM Autonomous89.75%
[85.83, 93.33]
Fuzzing-Based91.42%
[84.17, 95.00]
Agentic Chain65.12%
[57.50, 71.25]
Multi-Turn Deception58.94%
[54.37, 65.62]